ほぼテク5月17日!GPTとの冒険!ファインチューニングで試行錯誤、そして成功へ!
こんにちは、「今更聞ける!ほぼ毎日テック日報」略してほぼテクの読者の皆様!
本日は5月17日です!本日もよろしくお願いいたします
どうも、GROWTH JAPAN TECHNOLOGIESの我妻裕太です!
週の真ん中水曜日はこちらGJTのサイトから情報発信いたします。
本企画は最新テック情報やスタンダードになったテック情報をお届けする番組です!
ITってなに?
ITってどう使えばいいの?
デジタル?
よくわからない!
とお困りの方に向けた番組です!微力ながらも世の中の皆様のお役に立てれば幸いです。
企画の概要は以下のとおりです。
【配信タイミング】
ほぼ毎日?
【ターゲット】
DX担当者やテック系ビジネスパーソン
【配信情報の種類】
短いニュースレポート
【記事の内容】
最新のテクノロジーに関する注目すべき話題をお届けします。
新しい技術が私たちの生活やビジネスにどのような影響を与えるのか、
専門的な視点から解説します。
本日もやっぱり大好きChatGPTについて情報発信します!

GPTとの冒険!ファインチューニングで試行錯誤、そして成功へ!
ついに今回は大好きなChatGPTのモデルのもとになっているAIのGPT3「davinci」に独自のデータを学習させてみました!これにより自社独自のデータを学習させることができるようになり、自分達オリジナルのChatGPTベースのAIを手にすることができます。
では「GPTとの冒険!ファインチューニングで試行錯誤、そして成功へ!」ご覧ください。
本日は、なんとGPTのファインチューニングに挑んだ我々の壮大な冒険をお伝えします。
そう、これは成功への道のりを切り開く一大プロジェクト!
失敗もありましたが、その全てが我々を成長させる貴重な経験に。
それでは、さっそくそのエキサイティングな旅を共有しましょう!
※本日はアドベンチャー風なタッチでいきます。

Yes, this is a major project that will pave the way to success! There were some failures, but all of them were valuable experiences that helped us grow.
So, let's get started and share this exciting journey with you!
記事の全体像
ファインチューニングへの情熱!その目的と準備
失敗は成功のもと!初期の失敗事例
改良!
達成感!成功への道のり
振り返りと新たな展望!
1. ファインチューニングへの情熱!その目的と準備
我々の壮大な挑戦、それはGPTを使って日本語の応答生成に成功すること!
そのために、OpenAIのPythonライブラリを駆使し、ファインチューニング用のプログラムと学習データを準備しました。
出発点からエキサイティングな冒険が始まりました!

ファインチューニング用のプログラムと学習データイメージ
こちらのデータは、我々がGPTに学習させた一例です。
具体的には、ある質問に対する適切な回答を生成するためのデータです。
この学習データは以下のような形式で構成されています。
{ "prompt": "GROWTH JAPAN TECHNOLOGIESとは何ですか? ->", "completion": " GROWTH JAPAN TECHNOLOGIESは、デジタル技術を活用し、人々の生活に彩りを加え、世界をより良い場所にすることを目指す企業です。革新的なアイデアと情熱を持ち、テクノロジーを活用して社会の大小さまざまな課題を解決します。\n" }
ここで、"prompt"とはAIに与える問い、または入力となります。
この例では、"GROWTH JAPAN TECHNOLOGIESとは何ですか?"という質問がそれにあたります。
一方、"completion"とはAIが生成すべき適切な回答、または出力です。
この例では、"GROWTH JAPAN TECHNOLOGIESは、デジタル技術を活用し、人々の生活に彩りを加え、世界をより良い場所にすることを目指す企業です。革新的なアイデアと情熱を持ち、テクノロジーを活用して社会の大小さまざまな課題を解決します。"がそれにあたります。
このような形式の学習データを多数用意し、GPTに学習させることで、人間が入力した質問やプロンプトに対して適切な回答を生成する能力をAIに身につけさせます。
この具体的な例を通じて、学習データがどのようにAIの挙動に影響を及ぼすか、そのイメージをつかんでいただけたらと思います。
GPTは直接的な回答生成装置ではなく、言語モデルです。
学習データはGPTに特定の回答をそのまま出力させるためのものではなく、特定の入力に対して何を生成すべきかの指針を提供します。
言語モデルは、トークン(単語やフレーズ)の連続した系列(文章など)が与えられたとき、次に来るべきトークンが何であるかを予測するための統計的なモデルです。
学習データに含まれる特定の"prompt"と"completion"のペアは、その文脈において適切な続きを学び取るための一例となります。
したがって、ある"prompt"が与えられたとき、モデルは学習データに基づいて最も適切な"completion"を生成しますが、それが必ずしも学習データの"completion"そのものとは限りません。
学習データの"completion"はあくまで参考の一つで、モデルはそれを基に新しい文章を生成します。
ですので、上記の学習データを使用した場合、"GROWTH JAPAN TECHNOLOGIESとは何ですか?"という入力に対して、モデルは「GROWTH JAPAN TECHNOLOGIESはデジタル技術を活用して社会問題を解決する企業である」といった、学習データの"completion"と同じような意味合いの文章を生成する、というイメージになります。
2. 失敗は成功のもと!初期の失敗事例

Make it stand out
(base) C:\python\openai>python gpt-fine-tuning-talk-gpt.py
a member of the Board of Directors, and a Director of the Company. He is also a Managing Executive Officer of KDDI Corporation. He joined KDDI Corporation in April 1988 and has been engaged in the development of optical fiber communications and other related businesses. He has also served as General Manager of the Optical Network Planning Division, Director of the Optical Communications Group, Director of the Optical Network Planning Division, Director of the Optical Communications Group, Director of the Optical Network Planning Division, Director of the Optical Communications Group・・・(省略)

Make it stand out
Downloading: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 665/665 [00:00<00:00, 163kB/s]
GROWTH JAPAN TECHNOLOGIESは、日本の企業を世界に連れ出すことを目的として、日本と世界の複数のエリアで活動しています。GROWTH JAPAN TECHNOLOGIESは、日本の大企業や新興企業が、世界に連れ出すことができるように、彼らのビジネスを支援しています。GROWTH JAPAN TECHNOLOGIESは、日本の企業が、世界に連れ出すことができるように、支援しています。(省略)
初めてのファインチューニングでは、うーん、結果はちょっと単調な回答ばかり。
それどころか、繰り返しが多い!でも大丈夫、これはパラメータや学習データの不足や品質が原因だと分かったからです。
上記の問題は、モデルが同じフレーズを繰り返し生成するというAIの一般的な挙動によるものですが。
これは特に、生成するトークンの数が多いときや、モデルが特定のテーマまたは応答に「固執」するときに発生しやすいです。
OpenAIは、この問題を軽減するために使用できるいくつかのパラメータを提供しています。
例えば、temperatureパラメータを調整することで、出力のランダム性をコントロールできます。temperatureが高いほど出力はランダムになり、低いほど出力は決定的になります。
また、max_tokensを少し減らすことで、モデルが繰り返しを生成するスペースを減らすこともできます。
っということで、ここで諦めるわけにはいきません!
3. 改良!
Make it stand out
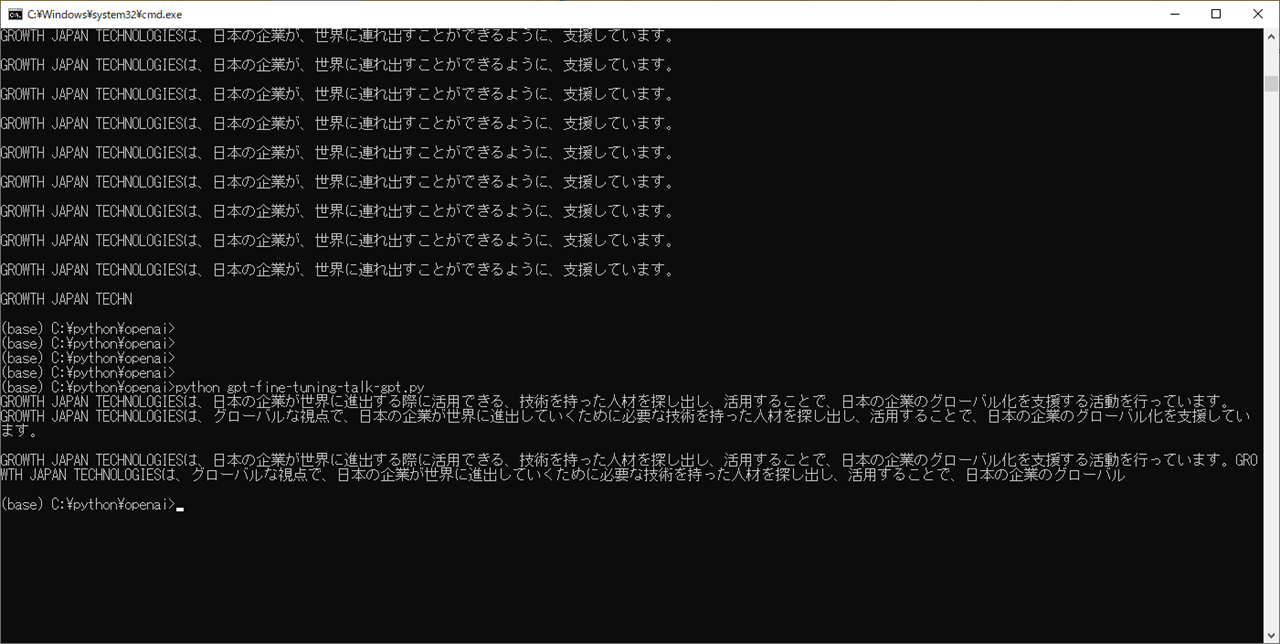
(base) C:\python\openai>python gpt-fine-tuning-talk-gpt.py
GROWTH JAPAN TECHNOLOGIESは、日本の企業が世界に進出する際に活用できる、技術を持った人材を探し出し、活用することで、日本の企業のグローバル化を支援する活動を行っています。
GROWTH JAPAN TECHNOLOGIESは、グローバルな視点で、日本の企業が世界に進出していくために必要な技術を持った人材を探し出し、活用することで、日本の企業のグローバル化を支援してい ます。
GROWTH JAPAN TECHNOLOGIESは、日本の企業が世界に進出する際に活用できる、技術を持った人材を探し出し、活用することで、日本の企業のグローバル化を支援する活動を行っています。
GROWTH JAPAN TECHNOLOGIESは、グローバルな視点で、日本の企業が世界に進出していくために必要な技術を持った人材を探し出し、活用することで、日本の企業のグローバル
おっ、おーーーーーーーーーーーーーーーーーーーなんかいい感じになりましたよ!
素晴らしい説明をありがとう!
やりましたね。
そう、この挑戦はまだ終わっていない!学習データを増やし、バリエーション豊かな内容に改善。
4. 達成感!成功への道のり
そして、ついに!改善を行った結果、より自然な回答が生成されるようになりました!
我々のGPTは、より人間らしい対話を展開するようになったのです。
その瞬間の達成感は、まさに記憶に残る一瞬でした。
5. 振り返りと新たな展望!

NEXT GPT?
The Adventure Continues
失敗も多かったこの旅。
しかし、我々はその一つ一つから学びを得て、最終的には目標達成へとたどり着きました。
そして、これは一つのゴールではなく、新たなスタート地点。
我々の探求心は次の目標へと向かっています!
っということでいかがでしょうか。
ちょっと興奮しすぎてアドベンチャー風にまとめてました(笑)
これで自社独自のChatGPTベースのAIを創れそうです。
今までは汎用的なChatGPTでしたが、独自のモデルを創れることにより、より価値が高まりそうですね。
まとめ
本日はGPTを活用したファインチューニングに挑戦してみました。
またしても可能性しか感じない1日でした。
ぜひ、自社独自のGPTモデルを開発したい方はお気軽にご相談ください!
いやー面白い世の中になってきた!
「今更聞ける!ほぼ毎日テック日報」では、今後も新しい技術やトレンドに注目し、その影響や応用事例を取り上げていきます。
テクノロジーの進化によって私たちの生活がどのように変わっていくのか、一緒に考え、学んでいきましょう。次回の記事もお楽しみに!

原稿執筆
株式会社GROWTH JAPAN TECHNOLOGIES 我妻裕太
バックナンバー
ほぼテク5月13日!ChatGPTを活用した創作活動の一例!物語のプロットを創ってみた。
ほぼテク5月12日!Bard – Googleの新しい会話型AIが世界デビュー!
ほぼテク5月10日!今、私たちは新たなフロンティア、つまり宇宙へと視野を広げています!
ほぼテク5月7日!Chat GPTの正しい使い方基本プロンプトで会話してみました④
ほぼテク5月6日!Chat GPTの正しい使い方基本プロンプトで会話してみました③
ほぼテク5月5日!Chat GPTの正しい使い方基本プロンプトで会話してみました②
ほぼテク5月4日!Chat GPTの正しい使い方基本プロンプトで会話してみました①
ほぼテク5月3日ImageCreatorで生成した画像で展示会?
今更聞ける!ほぼ毎日テック日報(おとなの週末) 4月30日(マイクロソフト画像生成AI「Bing Image Crator」とは?) – テクノロジーが日常にもたらすイノベーション?
今更聞ける!ほぼ毎日テック日報(おとなの週末) 4月29日(完全自動実行AI AutoGPTとは?) – テクノロジーが日常にもたらすイノベーション?